Today we presented our tutorial ‘DISCOVERING GENDER BIAS AND DISCRIMINATION IN LANGUAGE’ at the online Socinfo2020 conference. It was a great experience for all of us, hope you all enjoyed it! The live session was recorded by the organizers and will probably be shared online very soon.
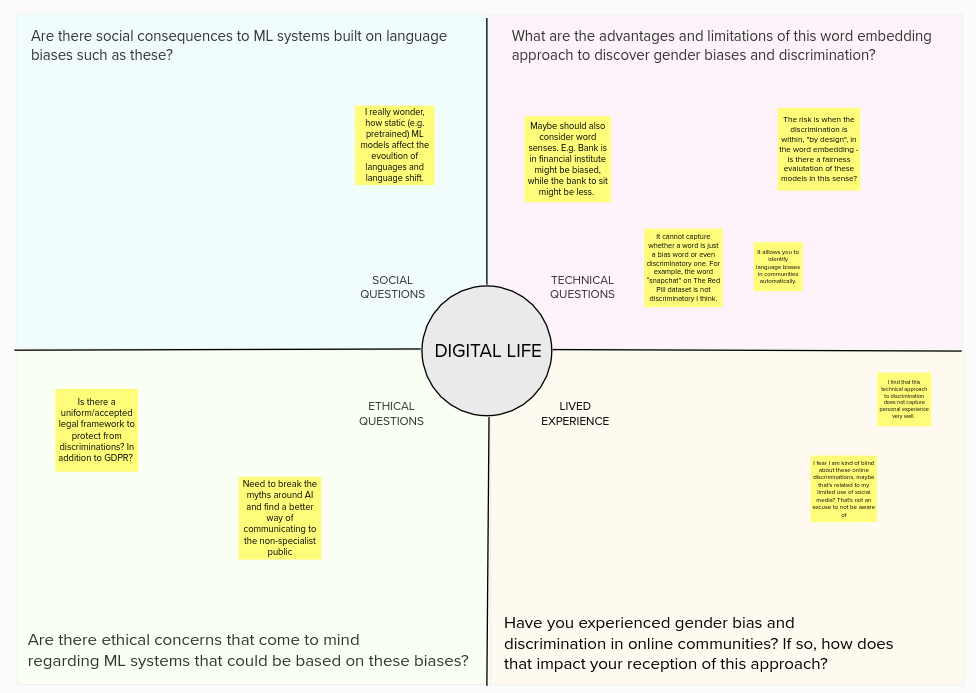
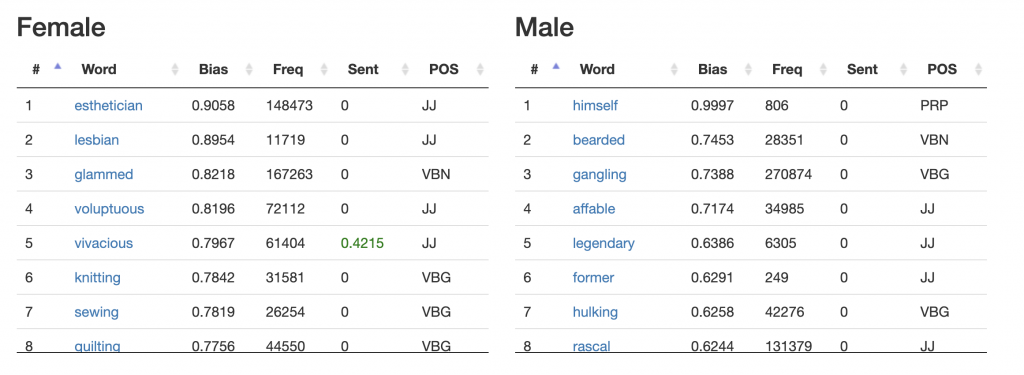
The tutorial focuses on the issue of digital discrimination, particularly towards gender. Its main goal is to help participants improve their digital literacy by understanding the social issues at stake in digital (gender) discrimination, and learning about technical applications and solutions. The tutorial is divided in four parts: it basically iterates twice through the social and technical dimensions. We make use of our own research in language modelling and Word Embeddings in order to clarify how human gender biases may be incorporated into AI/ML models. We first offer a short introduction to digital discrimination and (gender) bias. We give examples of gender discrimination in the field of AI/ML, and discuss the clear gender binary (M/F) that is presupposed when dealing with a computational bias towards gender. We then move to a technical perspective, introducing the DADD Language Bias Visualiser which allows us to discover and analyze gender bias using Word Embeddings. Finally, we show how computational models of bias and discrimination are built on implicit binaries, and discuss with participants the difficulties pertaining to these assumptions in times of post-binary gender attribution.